Data Processing (Sahara)
Sahara aims to provide users with simple means to provision a Hadoop cluster by specifying several parameters like Hadoop version, cluster topology, nodes hardware details and a few more.
Clusters
A cluster deployed by Sahara consists of node groups. Node groups vary by their role, parameters and number of machines. The picture below illustrates an example of a Hadoop cluster consisting of 3 node groups each having a different role (set of processes).
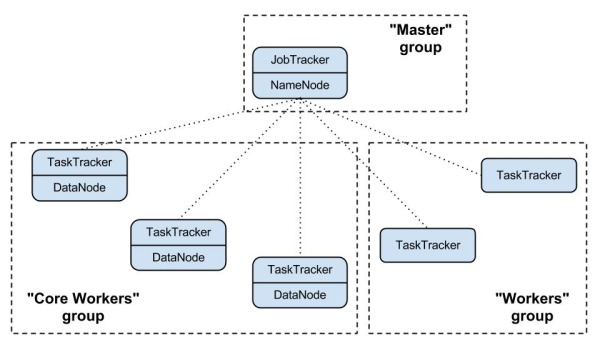
Node group parameters include Hadoop parameters like io.sort.mb or mapred.child.java.opts, and several infrastructure parameters like the flavor for VMs or storage location (ephemeral drive or Cinder volume).
A cluster is characterized by its node groups and its parameters. Like a node group, a cluster has Hadoop and infrastructure parameters. An example of a cluster-wide Hadoop parameter is dfs.replication. For infrastructure, an example could be image which will be used to launch cluster VMs.
Source: http://docs.openstack.org/developer/sahara/userdoc/overview.html
Querying
Listing available Clusters
List<? extends Cluster> clusters = os.sahara().clusters().list();
Finding a Cluster by ID
Cluster cluster = os.sahara().clusters().get(clusterId);
Creating a Cluster
Cluster cluster = os.sahara().clusters()
.create(Builders.cluster()
.name("def-cluster")
.pluginName("vanilla")
.hadoopVersion("2.6.0")
.template(clusterTemplateId)
.image(imageId)
.keypairName("mykeypair")
.managementNetworkId(networkId)
.build());
Deleting a Cluster
ActionResponse resp = os.sahara().clusters().delete(clusterId);
Scaling
Add Node Groups
Cluster cluster = os.sahara().clusters().addNodeGroup(clusterId, Builders.nodeGroup()
.count(3)
.name("b-worker")
.nodeGroupTemplateId(templateId)
.build());
Resizing Node Groups
Cluster cluster = os.sahara().clusters().resizeNodeGroup(clusterId, "worker", 4);
Cluster Templates
In order to simplify cluster provisioning Sahara employs the concept of templates.
There are two kinds of templates: node group templates and cluster templates. The former is used to create node groups, the latter
- clusters. Essentially templates have the very same parameters as corresponding entities. Their aim is to remove the burden of specifying all of the required parameters each time a user wants to launch a cluster.
Querying
Listing Cluster Templates
List<? extends ClusterTemplate> clusters = os.sahara().clusterTemplates().list();
Finding a Cluster by ID
ClusterTemplate ctemplate = os.sahara().clusterTemplates().get(templateId);
Creating a Cluster Template
ClusterTemplate ctemplate = os.sahara().clusterTemplates()
.create(Builders.clusterTemplate()
.name("cluster-template")
.pluginName("vanilla")
.hadoopVersion("2.6.0")
.managementNetworkId(networkId)
.addNodeGroup(Builders.nodeGroup()
.name("worker")
.count(3)
.nodeGroupTemplateId(templateId)
.build())
.addNodeGroup(Builders.nodeGroup()
.name("master")
.count(3)
.nodeGroupTemplateId(templateId)
.build())
.build());
Deleting a Cluster Template
ActionResponse resp = os.sahara().clusterTemplates().delete(templateId);
Plugins
A plugin object defines the Hadoop or Spark version that it can install and which configurations can be set for the cluster.
Querying
Listing all Plugins
List<? extends Plugin> plugins = os.sahara().plugins().list();
Getting a Plugin by Name
Plugin plugin = os.sahara().plugins().get("vanilla");
Getting a Plugin by Name and Version
Plugin plugin = os.sahara().plugins().get("vanilla", "2.4.1");
Conversion
Some plugins have specific configuration files. The following example shows the ability to convert a plugin specific configuration info a cluster template.
ClusterTemplate ctemplate = os.sahara().plugins()
.convertConfig("vanilla", "2.4.1", "My Template", Payloads.create(file));
Image Registry
The image registry is a tool for managing images. Each plugin lists required tags for an image. The Data Processing service also requires a user name to log in to an instance’s OS for remote operations execution.
The image registry enables you to add tags to and remove tags from images and define the OS user name.
Querying
Listing Images
List<? extends Image> images = os.sahara().images().list();
Listing Images with Tags
List<? extends Image> images = os.sahara().images().list("tag 1", "tag 2", "etc");
Finding an Image by ID
Image image = os.sahara().images().get(imageId);
Registering / Unregistering
Register Image
Image image = os.sahara().images().register(imageId, "ubuntu", "Ubuntu image for Hadoop 2.6.0");
Unregister Image
ActionResponse resp = os.sahara().images().unregister(imageId);
Tagging
Add tags to Image
Image image = os.sahara().images().tag(imageId, "vanilla", "2.6.0", "some_other_tag");
Remove tags from an Image
Image image = os.sahara().images().untag(imageId, "some_other_tag");
Node Group Templates
A cluster is a group of nodes with the same configuration. A node group template configures a node in the cluster.
A template configures Hadoop processes and VM characteristics, such as the number of reduce slots for task tracker, the number of CPUs, and the amount of RAM. The template specifies the VM characteristics through an OpenStack flavor.
Querying
Listing Node Group Templates
List<? extends NodeGroupTemplate> ngtemplates = os.sahara().nodeGroupTemplates().list();
Finding a Node Group Template by ID
NodeGroupTemplate ngtemplate = os.sahara().nodeGroupTemplates().get(templateId);
Creating a Node Group Template
NodeGroupTemplate ngtemplate = os.sahara().nodeGroupTemplates()
.create(Builders.nodeGroupTemplate()
.name("master")
.pluginName("vanilla")
.hadoopVersion("2.6.0")
.addNodeProcess("namenode")
.addNodeProcess("resourcemanager")
.addNodeProcess("oozie")
.addNodeProcess("historyserver")
.flavor("42")
.floatingIpPool(networkId)
.build());
Deleting a Node Group Template
ActionResponse resp = os.sahara().nodeGroupTemplates().delete(templateId);